Problems tagged with "RBF networks"
Problem #119
Tags: quiz-05, RBF networks, lecture-10
Suppose a Gaussian RBF network \(H(\vec x) : \mathbb{R}^2 \to\mathbb{R}\) is trained on a binary classification dataset using four Gaussian RBFs located at \(\vec\mu_1 = (0,0)\), \(\vec\mu_2 = (1,0)\), \(\vec\mu_3 = (0,1)\), and \(\vec\mu_4 = (1,1)\).
All four RBFs use the same width parameter, \(\sigma\).
After training, it is found that the weights corresponding to the four basis functions are \(w_1 = -3\), \(w_2 = 3\), \(w_3 = 3\), \(w_4 = -3\).
Which of the below could show the decision boundary of \(H\)? The plusses and minuses show where the prediction function, \(H\), is positive and negative.
Solution
The second plot is correct.
The weights \(w_2 = 3\) and \(w_3 = 3\) are positive at \((1,0)\) and \((0,1)\), while \(w_1 = -3\) and \(w_4 = -3\) are negative at \((0,0)\) and \((1,1)\). This means \(H\) is positive near \((1,0)\) and \((0,1)\) and negative near \((0,0)\) and \((1,1)\). The decision boundary separates these regions, running diagonally through the square.
Problem #120
Tags: lecture-10, quiz-05, RBF networks, feature maps
Let \(\mathcal{X} = \{(\vec{x}^{(1)}, y_1), \ldots, (\vec{x}^{(100)}, y_{100})\}\) be a dataset of 100 points, where each feature vector \(\vec{x}^{(i)}\in\mathbb{R}^{50}\). Suppose a Gaussian RBF network is trained using 25 Gaussian basis functions.
Recall that a Gaussian RBF network can be viewed as mapping the data to feature space, where a linear prediction rule is trained. In the above scenario, what is the dimensionality of this feature space?
Solution
\(25\).
Each Gaussian basis function produces one feature (the output of that basis function applied to the input). With 25 basis functions, the feature space is \(\mathbb{R}^{25}\). The dimensionality of the feature space equals the number of basis functions, not the original input dimension.
Problem #121
Tags: quiz-05, RBF networks, lecture-10
Does standardizing features affect the output of a Gaussian RBF network?
More precisely, let \(\mathcal{X} = \{(\vec{x}^{(1)}, y_1), \ldots, (\vec{x}^{(n)}, y_n)\}\) be a dataset, and let \(\mathcal{Z} = \{(\vec{z}^{(1)}, y_1), \ldots, (\vec{z}^{(n)}, y_n)\}\) be the dataset obtained by standardizing each feature in \(\mathcal{X}\)(that is, each feature is scaled to have unit standard deviation and zero mean). Note that the \(y_i\)'s are not standardized -- they are the same in both datasets.
Suppose \(H_\mathcal{X}(\vec{x})\) is a Gaussian RBF network trained by minimizing mean squared error on \(\mathcal{X}\), and \(H_\mathcal{Z}(\vec{z})\) is a Gaussian RBF network trained by minimizing mean squared error on \(\mathcal{Z}\). Both RBF networks use the same width parameters, \(\sigma\). The centers used in \(H_\mathcal{Z}\) are obtained by standardizing the centers used in \(H_\mathcal{X}\) using the mean and standard deviation of the data, \(\vec{x}^{(i)}\).
True or False: it must be the case that \(H_\mathcal{X}(\vec{x}^{(i)}) = H_\mathcal{Z}(\vec{z}^{(i)})\) for all \(i \in\{1, \ldots, n\}\).
Solution
False.
Standardizing changes the distances between points and centers. The Gaussian basis function \(\varphi(\vec{x}; \vec{\mu}, \sigma) = e^{-\|\vec{x} - \vec{\mu}\|^2 / \sigma^2}\) depends on the Euclidean distance \(\|\vec{x} - \vec{\mu}\|\). While the centers are standardized along with the data, the width parameter \(\sigma\) remains the same. Since standardizing changes the scale of the features (and thus the distances), using the same \(\sigma\) will produce different basis function outputs, leading to different predictions.
Problem #122
Tags: quiz-05, RBF networks, lecture-10
Consider the following labeled data set of three points:
A Gaussian RBF network \(H(x) : \mathbb{R}\to\mathbb{R}\) is trained on this data with two Gaussian basis functions of the form \(\varphi_i(x; \mu_i, \sigma_i) = e^{-(x - \mu_i)^2 / \sigma_i^2}\). The centers of the basis functions are at \(\mu_1 = 2\) and \(\mu_2 = 6\), and both use a width parameter of \(\sigma = \sigma_1 = \sigma_2 = 1\).
Suppose the RBF network does not have a bias parameter, so that the prediction function is \(H(x) = w_1 \varphi_1(x) + w_2 \varphi_2(x)\).
What is \(w_1\), approximately? Your answer may involve \(e\), but should evaluate to a number.
Solution
\(w_1 \approx 3e\).
We evaluate the basis functions at each data point. Note that when a basis function center is far from a data point, the Gaussian evaluates to approximately zero.
At \(x_1 = 1\): \(\varphi_1(1) = e^{-(1-2)^2} = e^{-1}\) and \(\varphi_2(1) = e^{-(1-6)^2} = e^{-25}\approx 0\).
At \(x_3 = 6\): \(\varphi_1(6) = e^{-(6-2)^2} = e^{-16}\approx 0\) and \(\varphi_2(6) = e^{0} = 1\).
So \(H(1) \approx w_1 e^{-1} = y_1 = 3\), giving \(w_1 \approx 3e\). Similarly, \(H(6) \approx w_2 = y_3 = 3\), confirming \(w_2 \approx 3\).
Problem #123
Tags: lecture-10, quiz-05, RBF networks, feature maps
Consider a Gaussian RBF network with three basis functions of the form \(\varphi_i(\vec x) = e^{-\|\vec x - \vec \mu^{(i)}\|^2 / \sigma^2}\), where \(\sigma = 2\) for all basis functions. The centers \(\vec\mu^{(1)}\), \(\vec\mu^{(2)}\), and \(\vec\mu^{(3)}\) are shown as black \(\times\) markers in the figure below.
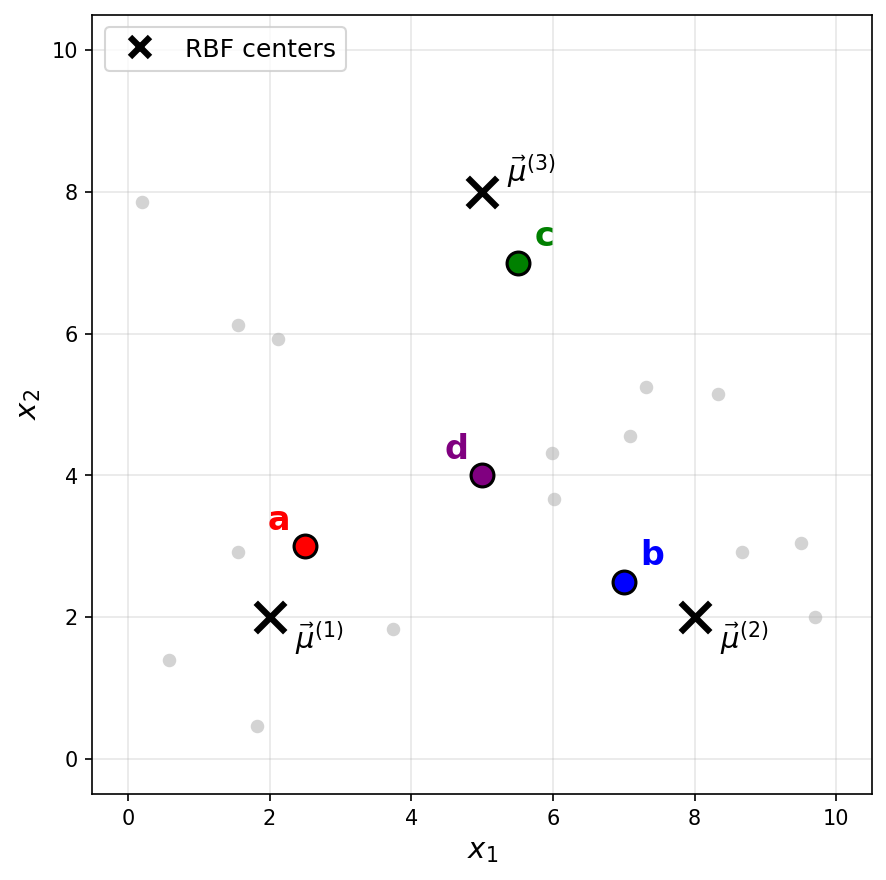
Recall that a Gaussian RBF network can be viewed as mapping data points to a feature space, where the new representation of a point \(\vec x\) is:
Suppose a point \(\vec x\) has the following feature representation:
Which of the labeled points (a, b, c, or d) could be \(\vec x\)?
Solution
The answer is c.
The feature representation tells us that \(\varphi_1(\vec x) \approx 0\), \(\varphi_2(\vec x) \approx 0\), and \(\varphi_3(\vec x) \approx 0.73\).
Since a Gaussian basis function \(\varphi_i(\vec x) = e^{-\|\vec x - \vec \mu^{(i)}\|^2 / \sigma^2}\) outputs values close to 1 when \(\vec x\) is near the center \(\vec\mu^{(i)}\) and values close to 0 when \(\vec x\) is far from the center, the feature representation indicates that \(\vec x\) is far from \(\vec\mu^{(1)}\) and \(\vec\mu^{(2)}\)(since \(\varphi_1 \approx 0\) and \(\varphi_2 \approx 0\)), but relatively close to \(\vec\mu^{(3)}\)(since \(\varphi_3 \approx 0.73\)).
Looking at the figure, point c is the only point that is close to \(\vec\mu^{(3)}\) and far from both \(\vec\mu^{(1)}\) and \(\vec\mu^{(2)}\).
Problem #124
Tags: lecture-10, quiz-05, RBF networks, feature maps
Consider a Gaussian RBF network with three basis functions of the form \(\varphi_i(\vec x) = e^{-\|\vec x - \vec \mu^{(i)}\|^2 / \sigma^2}\), where \(\sigma = 3\) for all basis functions. The centers \(\vec\mu^{(1)}\), \(\vec\mu^{(2)}\), and \(\vec\mu^{(3)}\) are shown as black \(\times\) markers in the figure below.
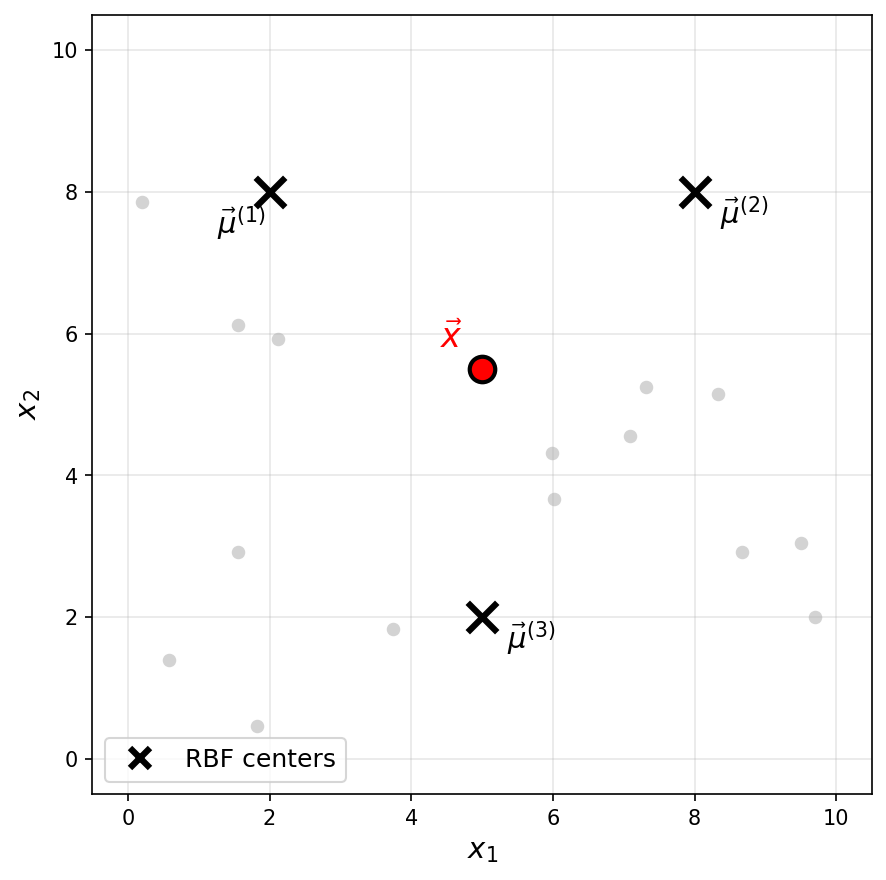
Recall that a Gaussian RBF network can be viewed as mapping data points to a feature space, where the new representation of a point \(\vec x\) is:
One of the following is the feature representation of the highlighted point \(\vec x\). Which one?
Solution
The answer is \(\vec f(\vec x) \approx(0.18, 0.18, 0.26)^T\).
The highlighted point \(\vec x\) is not particularly close to any of the three centers. It is roughly equidistant from \(\vec\mu^{(1)}\) and \(\vec\mu^{(2)}\), and slightly closer to \(\vec\mu^{(3)}\).
Since a Gaussian basis function outputs values close to 1 only when the input is very near the center and decays toward 0 as the distance increases, we expect all three basis functions to output moderate, nonzero values. This rules out the first three options, which each have one large value and two zeros (corresponding to a point very close to a single center).